Syntax Elements & Powerful Functions
Overview
Teaching: 60 min
Exercises: 40 minQuestions
What elements of Python syntax might I see in other people’s code?
How can I use these additional features of Python to make my code more succinct and easier to read?
What built-in functions and standard library modules are recommended to improve my code?
Objectives
recognize all elements of modern Python syntax and explain their purpose.
understand and write functions designed to make common tasks easier and simpler to maintain.
improve code readability and efficiency by using expressive functions and comprehensions.
A brief recap
In your experience with Python up to know you have likely come across some, if not all, of the following elements
Syntax
dot (.)operator as inmylist.append- used to access member attributes or functionsindentation- a distinctive feature of Python; spacing to the left of the code is used to demark blocks of codeOperators
==,!=- equality and inequality>,>=,<,<=- used to compare if numbers are smaller/greater or equal to others+,-,*,/,//,%,**- addition, subtraction, multiplication, division, floor or integer division, modulo, power operators+=,-=,*=,/=,//=,%=,**=- short assign operators -x += 1is a short and more efficient variant ofx = x + 1and,or,not- logical operators -notnegates a condition:not True == Falseis- evaluate identity - see the difference between==(equality) andis(identity)Basic types
True,False- Boolean type, implicit to any condition evaluated byif.None- a special value used to represent nothing - also what remains from a function that has no return valueint,float,complex- numerical typesstr- the most common text typelistor[],dictor{}- mutable containers, capable of holding other types and expanding/shrinking on demandtupleor()- immutable container, often used for read-only dataControl flow
if,elif,else- used to construct conditional stepsfor,in- to iterate finite objects and repeat actionsFunctions & Imports
def,return- used to define functions; reusable pieces of code that can be called from elsewherefrom,import- to load modules, classes and functions from other Python scripts
Far and beyond
In this session we will cover additional syntactic elements providing examples of their use along the way.
- Keywords
- Sets
- String formatting
- Tracebacks and exceptions
- Advanced function definition
- Comprehensions
- File handling and
with - Useful standard library modules
- Python code in the wild
- Additional resources
Many keywords
When using a text editor that is capable of coloring the code, referred to as syntax highlighting, you may find that certain words are colored differently.
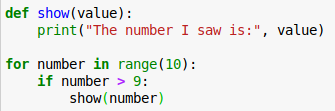
For instance in the above example, the green bold words: def, for, in and if are keywords,
while print() and range() are built-in functions.
Notice that show() is also a function but in this editor it is shown without a distinctive color or font.
Later on we will see examples of the following additional keywords: del, while, continue, break, pass, yield, with, try and raise.
In case you are wondering, you can obtain the complete list of Python keywords by executing the following code:
import keyword
print(keyword.kwlist)
which in Python 3.7 prints:
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break',
'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally',
'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal',
'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
delete what is no longer needed
The del keyword is used to delete elements from containers such as list and dict
or to delete variables and the associated data from memory.
The latter can be particularly useful to get rid of large objects in memory.
shopping_list = ["knife", "pan", "mask"]
shopping_quantities = {
"apples": 4,
"grapes": 2,
"cherries": 20
}
# If we changed our mind and no longer needed a pan we could
del shopping_list[1]
1.1. Shop is closed
shopping_list = ["knife", "pan", "mask"] shopping_quantities = { "apples": 4, "grapes": 2, "cherries": 5 }From a friend, you learn that the utilities shop is closed and that the grocery shop was out of grapes. Use the
delkeyword to delete the shopping_list and removegrapesfromshopping_quantities.Solution
for good measure while we are here
When trying to repeat actions in your code, such as applying a mathematical operation to a list of numbers,
you typically resort to using a loop.
Python provides two kinds of loops. The for and the while loop.
The main distinction between them is that for provides a way of looping over an
iterable object whereas while continues looping as long as a given condition evaluates to True.
Taking our shopping lists from before:
quantities = {
"apples": 4,
"cherries": 5,
"grapes": 2,
"knife": 1,
"mask": 1,
"pan": 1,
}
cost = {
"apples": 2,
"cherries": 5,
"grapes": 5,
"knife": 10,
"mask": 1,
"pan": 15,
}
and defining a function to simplify calculating the total bill
def total_cost(cart, cost):
total = 0
for item, quantity in cart.items():
total += cost[item] * quantity
return total
and since we absolutely love cherries, we decide that we will get as many cherries as we can with our budget, but we still want to keep some change.
money_to_spend = 90
some_change = 10
available_money = money_to_spend - some_change
while total_cost(quantities, cost) < available_money :
quantities["cherries"] += 1
print("Increasing cherries to", quantities["cherries"])
print("With", money_to_spend, "we can buy:")
print(quantities)
money_spent = total_cost(quantities, cost)
money_left = money_to_spend - money_spent
print("Spending in total", money_spent, "and keeping", money_left, "of change")
giving us:
Increasing cherries to 6
Increasing cherries to 7
Increasing cherries to 8
With 90 we can buy:
{'knife': 1, 'pan': 1, 'mask': 1, 'apples': 4, 'grapes': 2, 'cherries': 8}
Spending in total 84 and keeping 6 of change
In addition, both for and while, like if can also have an else clause
and make use of continue and break statements.
continue causes the loop to skip to the next cycle
while break causes it to stop looping and resume after the indentation.
The else keyword can also be used to execute instructions when the loop reaches the end.
In the case of for this means, after iterating the last element and
in the case of while, if the condition is no longer true.
for i in (1, 2, 3, 4, 5, 6, 7, 8):
if i == 6:
break
if i < 3:
continue
print("Loop number", i)
print("We are done with the loop")
which produces
Loop number 3
Loop number 4
Loop number 5
We are done with the loop
1.2. Or else …
Compare:
i = 0 while True: i += 1 print("Cycle", i) if i >= 5: break else: print("We reached the end")and
i = 0 while i < 5: i += 1 print("Cycle", i) else: print("We reached the end")
- Which of the two examples doesn’t execute the instructions in the
elseblock?- How could you modify this example so that the
elseblock is executed?Solution
Setting things straight
When working with collections of objects, finding common patterns or building a Venn diagram,
you may feel tempted to calculate union and intersection using list and for loops,
but you will quickly find that these structures are sub-optimal for the task at hand.
Despair not, Python has set as a built-in container type.
Sets, after the mathematical discipline of set theory
are very efficient and easy to use to calculate intersections and check for membership.
set is a container with two distinctive characteristics.
Much like dictionaries, and in contrast to lists and tuples
they do not allow element repetition and have no intrinsic order of elements.
Like all built-in containers, sets can store any type of object.
A set can be defined by converting another container or by using the {} notation,
separating objects by commas, much like in lists.
codons = ["AUG", "AUA", "AUG", "AUC"]
unique_codons = set(codons)
print(unique_codons)
will result in:
{'AUA', 'AUC', 'AUG'}
1.3. Dictionaries and sets
Although dictionaries and sets share the syntax notation
{}they can be distinguished by their content.Here is a particularly contrived example to highlight the difference. Can you tell which is the
dictionary and which is theset?objA = {"one", 1, "two", 2} objB = {"one": 1, "two": 2}Solution
1.4. Common ground
Calculate the word overlap of 3 sentences. Use a for loop such that your code would work with an arbitrary number of sentences.
Given:
sentences = [ "A list can hold any type of object", "A set is a type of object that doesn't keep element order", "A tuple, like a string, is an immutable type", "Strings are immutable, any change doesn't affect the original", "Dictionaries can only use immutable types as keys" ]the output should be:
Between the first 2 sentences there are 4 common words: A, object, of, type Between the first 3 sentences there are 2 common words: A, type After 4 sentences, there are no common wordsSolution
Whenever you want to find out if a value exists in a collection, but don’t care
about where in that collection it exists,
your code will run much faster if you’re looking up those values
in a set (or dictionary), instead of a list.
String formatting variants
When dealing with or producing text using content stored in different variables
you may find yourself using the + operator to concatenate strings.
If you tried, you may have quickly noticed that combining different types makes Python unhappy.
text = "I have"
count = 10
fruit = "cherries"
message = text + " " + count + " " + fruit
results in the error:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str
and so, in order to avoid the error one would have to explicitly convert count to a string.
message = text + " " + str(count) + " " + fruit
print(message)
I have 10 cherries
Yet, doing this manually is error prone and rather unreadable.
To simplify this process Python introduced alternative ways to achieve this action known as string formatting.
Old style
Since Python 2.x the alternative way is to use placeholders, such as %s, and the % operator
message = "%s %s %s" % (text, count, fruit)
print(message)
I have 10 cherries
Notice that we didn’t have to use str() around count.
Since we use %s as placeholder, we implicitly request that the value is converted
to its string representation.
You can find information about alternative placeholders and syntax in the old formatting style python documentation.
While powerful, this formatting style was considered impractical or limiting in some situations.
Later versions of Python introduced the .format() approach also known as new style.
New style
Similarly to the old style, we need to provide a string placeholder, in this case {}.
message = "{} {} {}".format(text, count, fruit)
print(message)
I have 10 cherries
Although the above example reads exactly the same with old and new style, the latter allows additional flexibility and formatting options.
For instance, referring to the same value more than once and formatting variables in a different order to the text is not possible at all using the old style.
This can be inconvenient e.g. when we want to create a string using values that are always returned from a function in a particular order.
With the new style we can:
message = "{2} {1} and I mean only {1} {0}".format(fruit, count, text)
print(message)
I have 10 and I mean only 10 cherries
Alternative formatting options and a comparison between old and new style can be found in the very useful pyformat.info website.
And as powerful as .format() is,
the Python community still considered this solution overly verbose.
And so since Python 3.6 a new construct called f-strings was introduced.
F-strings
f-strings are as powerful as .format() but with a simplified syntax.
Reusing the previous example, now with f-strings we would do:
message = f"{text} {count} and I mean only {count} {fruit}"
print(message)
I have 10 and I mean only 10 cherries
Notice how we got rid of the .format() part and instead have a little f before the string.
f-strings are the third string prefix after raw string literals identified by the r prefix
and unicode string literals identified by u.
Expecting the unexpected
So far, we have seen how Python looks when things work as expected.
However, every once in a while, you will run into errors.
We saw this before when we tried to concatenate 10 + "cherries" without str(10).
Errors in Python are called exceptions and the message displayed is called a traceback. The exception name is usually present in the last line of a traceback, together with a description of what might have gone wrong. Tracebacks help us identify where the error happened, while the exception tells us what went wrong.
10 + "cherries"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'int' and 'str'
In this case the traceback tells us that we triggered a TypeError exception,
caused by trying to use the + operator on incompatible types int and str.
Since we are using a python interactive shell the rest is not particularly informative.
The above traceback is rather short but in real programs, which make use of complex libraries, they can get surprisingly long:
But fear not, although scary at first, learning how to read a traceback is halfway to becoming great at debugging your programs and being a better programmer.
As an example, here is a longer traceback where we can see an exception that occurred while using Flask, a powerful library to build web applications.
Traceback (most recent call last):
File "/Py37/lib/python3.7/site-packages/flask/app.py", line 2449, in wsgi_app
response = self.handle_exception(e)
File "/Py37/lib/python3.7/site-packages/flask/app.py", line 1866, in handle_exception
reraise(exc_type, exc_value, tb)
File "/Py37/lib/python3.7/site-packages/flask/_compat.py", line 39, in reraise
raise value
File "/Py37/lib/python3.7/site-packages/flask/app.py", line 2446, in wsgi_app
response = self.full_dispatch_request()
File "/Py37/lib/python3.7/site-packages/flask/app.py", line 1951, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/Py37/lib/python3.7/site-packages/flask/app.py", line 1820, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/Py37/lib/python3.7/site-packages/flask/_compat.py", line 39, in reraise
raise value
File "/Py37/lib/python3.7/site-packages/flask/app.py", line 1949, in full_dispatch_request
rv = self.dispatch_request()
File "/Py37/lib/python3.7/site-packages/flask/app.py", line 1935, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "blogchat/routes.py", line 26, in chat
raise ValueError(f"Invalid chat room '{room}'")
ValueError: Invalid chat room 'test'
On the first line of the traceback we have the path to the file app.py,
part of the flask Python library.
We see also the name of the function that was being executed when the error occurred, wsgi_app, and the line 2449
from where the next function handle_exception was called.
wsgi_app is the name of the first function started by the flask application
and is therefore the first to be shown in the traceback.
From there, another function called another function which eventually
called our chat function where the ValueError exception occurred.
Additionally, we see that the exception is telling us that "test" is not a valid chat room.
So far, we’ve seen TypeError and ValueError.
Other common exceptions include SyntaxError, IndexError, KeyError, NameError and OSError.
If you regularly use other Python libraries such as numpy, pandas, scikit-learn and others,
you will likely encounter many others.
You should also be aware that exceptions are part of a hierarchy, displayed in
Python’s official exception documentation.
The relevance of this hierarchy will become clear once we learn how to handle and raise exceptions in the next section.
Ooops, now what?
As we saw before, exceptions are Python’s way of telling us that something went wrong. Exceptions by themselves are not fatal and do not immediately cause Python to quit. In fact, bug-free code can generate exceptions as part of their normal behavior and continue execution normally.
However, exceptions do have one particularity. They interrupt the flow of execution of code and, if unhandled, result in Python exiting.
So how do you handle exceptions?
Introducing the keywords: try, except and as, finally and, last but not least, raise.
We will also reuse the else keyword which, like with if, for and while, can be used to handle alternative cases.
Although not exclusive to exceptions, we will also see how to use the pass keyword to tell Python to do nothing.
Consider the following code:
x = 10
y = 0
print(x / y)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZeroDivisionError: division by zero
Since dividing by zero is mathematically undefined we have to avoid this operation or deal with the consequences. One possibility is to do:
if y:
print(x / y)
which allows us to avoid the cause of the problem.
Another possibility is to deal with the consequences:
try:
print(x / y)
except ZeroDivisionError:
print("We cannot divide by zero")
A lot is happening here so let’s break it down.
We use try to tell Python “I’m going to do something that might fail”,
and then we use except to ask “If you see a ZeroDivisionError, stop the exception and do this instead”.
Notice also that we use the exception name here.
Since ZeroDivisionError is a built-in exception, Python knows where to get it,
however if we were using other libraries we would have to import the exceptions
before referring to them. Failing to do so would cause a NameError exception,
which happens when we use a variable that was not defined in the current scope.
But wait, there’s more!
0 text = "Hello exceptions"
1 try:
2 complex_function(text)
3 except (IndexError, KeyError):
4 pass
5 except ValueError as e:
6 print("We likely failed to convert text to a number")
7 print("The original message is", e)
8 raise
9 except ZeroDivisionError:
10 print("We cannot divide by zero")
11 print("But we want to stop the exception and turn it into a ValueError")
12 print("which external code knows how to handle")
13 raise ValueError("complex_function tried to divide by zero")
14 else:
15 print("And we finished normally")
16 finally:
17 print("Phew that was a difficult one")
That’s a lot to digest!! Handling exceptions can be a tricky business so lets take this slow. We see:
- multiple uses of
except(lines 3, 5 and 9), within the sametry. - multiple exceptions being captured in a single
exceptclause (line 3). - the
passkeyword (line 4) which in this context tells Python “If you see anIndexErrororKeyErrordon’t do anything”. - the
askeyword (line 5) which allows us to capture the exception, give it a name - in this case,e- and do something with it (line 7). - the
raisekeyword, which, used by itself (line 8), re-raises the original exception and, with another exception in front (line 13), raises the specified exception instead. - the
elsekeyword (line 14), which only executes if no exception is raised during thetryblock. - the
finallykeyword (line 16), which always executes, regardless of what happened.
1.5. Fear not the exception
Training also our ability to identify problems, try to predict what exception, if any, is produced in the following code blocks.
a = "5" b = "6" a * bSolution
a = "5" b = int("6") a * bSolution
a = "5" b = float("6") a * bSolution
a = [1, 2, 3] sum(a)Solution
a = [1, 2, 3, "4"] sum(a)Solution
a = [1, 2, 3) sum(a)Solution
a = [1, 2, 3] sum[a]Solution
a = [1, 2, 3] a[3]Solution
a = {"one": 1, "two": 2} a[1]Solution
a = {"one": 1} a[a] = "two"Solution
1.6. Many ways to err
Returning to our complex example from before, define multiple versions of
complex_functionthat run through each of theexceptblocks and also theelseandfinallyat least once.data = {"msg": "Hello exceptions"} try: complex_function(data) except (IndexError, KeyError): print("Saw Index or KeyError") pass except ValueError as e: print("Saw ValueError with error message", e) raise except ZeroDivisionError: raise ValueError("complex_function tried to divide by zero") else: print("And we finished normally") finally: print("Phew that was a difficult one")for example, to run through the
IndexErrorexception we could have:def complex_function(data): return data["msg"][100]As a bonus challenge, can you think of solutions to all the above using only
raise? For example,def complex_function(data): raise IndexError()Solution(s)
Advanced function definition
So far we have seen functions with simple argument definitions:
def double(value):
return 2 * value
For more complex functions flexibility is often desirable. We can start by setting default values:
def multiply_by(value, multiplier=2):
return value * multiplier
multiply_by(5, 3) # returns 15
multiply_by(5) # returns 10
Note that setting default values influences the order in which you can define parameters in your function: once you set a default for one parameter, all subsequent parameters must also have a default value.
# this is fine
def make_it_bigger(a, b=100, c=20):
return a**(b * c)
# this will result in a SyntaxError
def make_it_bigger(a, b=100, c):
return a**(b * c)
Or allowing a variable number of arguments to be passed using * (often *args)
and ** (often **kwargs).
def multiply_by(*values, multiplier=2):
outputs = []
for value in values:
outputs.append(value * multiplier)
return outputs
multiply_by(1, 2, 3, 4, 5) # returns [2, 4, 6, 8, 10]
multiply_by(1, 2, 3, 4, 5, multiplier=3) # returns [3, 6, 9, 12, 15]
inputs = [1, 2, 3, 4, 5]
settings = {"multiplier": 3}
multiply_by(*inputs, **settings) # returns [3, 6, 9, 12, 15]
Note that the * and ** syntax can work both ways.
def catchall(*args, **kwargs):
print("Positional arguments:", args, "- Keyword arguments:", kwargs)
catchall(4, 3, 3, 5, name="John", age="23")
Positional arguments: (4, 3, 3, 5) - Keyword arguments: {'name': 'John', 'age': '23'}
1.7. The pirate function definition
A simple function definition uses fixed arguments occasionally with default values. Using
*and/or**define a single function that, given the following inputs:give_rum(2, "barrels", "crates", "glasses", to="Capt. Claw") give_rum(3, "jars", to="Capt. Sparrow") give_rum() giveaway = {"quantity": 2, "to": "Capt. Long John"} give_rum(**giveaway)produces the corresponding output:
Argh! 2 barrels, 2 crates and 2 glasses of rum to Capt. Claw Argh! 3 jars of rum to Capt. Sparrow Argh! 1 cup of rum to all the crew! Argh! 2 cups of rum to Capt. Long JohnSolution
1.8. The rogue cart
Consider the function:
def add_to_cart(item, cart=[]): cart.append(item) return cartwhich can be used to add items to a shopping cart
fruit_cart = ["apples", "oranges"] new_fruit_cart = add_to_cart("bananas", fruit_cart) print(new_fruit_cart) # This prints ["apples", "oranges", "bananas"]Given the example above, inspect also the original
fruit_cart. Does it contain what you expect?Since we set a default value for the
cartkeyword we can also call the function with anitemand a new cart will be created for us.veggies_cart = add_to_cart("tomatoes") print(veggies_cart)If you decide to create a new cart with kitchen utensils
utensils_cart = add_to_cart("knife")Does it contain the items you expect? What is going on here?
Solution
Argument expansion outside functions
The * and ** syntax can also be used outside functions to expand values:
a, *b, c = (1, 2, 3, 4, 5)
print(a)
print(b)
print(c)
1
[2, 3, 4]
5
or inversely:
together = (a, *b, c)
print(together)
(1, 2, 3, 4, 5)
Generators
You are now fully empowered (pun intended) to scale up your Python analysis.
Perhaps you will be using numpy or scikit-learn to analyse images.
Or have terabytes of sequencing data to go through.
As you start loading this data and storing it in any of the containers we’ve seen
up to now (list, dict, set), you’ll soon realize that they are too big
or there are too many to keep in memory at all times.
A possible solution is to transform some of your functions into generators.
Generators, as you may guess from the name, create data as they go. They further contrast with functions by only generating as many results as necessary for one iteration before pausing. This means they could potentially be used to create an infinite number of results. However, a caveat also inferable from this approach is that they can only generate the data once and have no persistence. If you wish to keep the result of a generator, you will need to decide how to accumulate its output.
To define a generator, we use yield in addition to return inside a function definition.
def my_multiplier(startvalue, multiplier, stopvalue):
while startvalue < stopvalue:
yield startvalue
startvalue *= multiplier
mygen = my_multiplier(5, 2, 50)
print(mygen)
<generator object my_multiplier at 0x_random_mem>
at this point we have defined a generator but have yet to use it.
The most common way to use it is to iterate over its elements using a for loop
or combining a while loop with the function next().
We could also convert it to a different container with list(mygen) or set(mygen).
for result in mygen:
print(result)
5
10
20
40
When using the next() function we have to be aware that if a generator is exhausted
a StopIteration exception is raised.
Left uncaught, this exception will cause our program to exit prematurely.
We therefore need to use:
mygen = my_multiplier(5, 2, 50)
while True:
try:
result = next(mygen)
except StopIteration:
print("StopIteration was raised")
break
print(result)
5
10
20
40
StopIteration was raised
An additional feature of generators is that they allow two-way communication.
Instead of next(mygen) you can use mygen.send() to send data to the generator.
Using .send() will cause the generator to receive a value and iterate to the next step.
1.9. Yield or return to battle
Is the following definition valid Python? What kind of function is it? Is the number
2accessible somehow? (Hint: you may find it helpful to refer back to the earlier section on handling exceptions.)def get_values(): return 2 yield 1Solution
1.10. Yield back
While making use of the
back_and_forthgenerator but without modifying its source, modify the following code to print multiples of 2, on screen, one per line, starting with2and ending with20. No other output should be visible.def back_and_forth(): for i in range(10): j = yield i print(j) my_gen = back_and_forth() # add and/or modify code below this line value = next(my_gen)Do you think it’s possible to solve this challenge by iterating the generator using
for value in my_gen?Solution
Comprehensions
Comprehensions are a more succinct form of a loop with an accumulator. While succinct and powerful, one should use this syntax with moderation, as complex comprehensions can sacrifice readability in favor of compactness.
If a list of elements can be created with:
inputs = [1, 5, 10, 50, 100]
output = []
for i in inputs:
if i >= 10:
output.append(i / 10)
print(output)
[1.0, 5.0, 10.0]
the equivalent code using a list comprehension is:
inputs = [1, 5, 10, 50, 100]
output = [i / 10 for i in inputs if i >= 10]
print(output)
and the result is exactly the same:
[1.0, 5.0, 10.0]
While list comprehensions are the most widely used,
this syntax can be used with generators, lists, sets, and dicts,
The syntax for each is:
(x for x in y)- generator[x for x in y]-list{x for x in y}-set{a: b for (a, b) in d}-dict
What about tuples
An avid reader will notice that
tupleis not listed. The reason is that the syntax for a generator comprehension is the same as fortuple.While
tuple(x for x in y)results in atuple, a performance evaluation of this code will show a degradation asyincreases size.
File handling and with
Pandas and numpy
In subsequent lessons you will be introduced to alternative ways to read data into your Python session. These will be specific to
pandasandnumpy.
If you want to read from or write to a file in Python you would typically use the
open() function, which returns a handle to the file you specified together with one of a few modes.
If reading text rt, if writing text wt, if reading binary rb and similarly if writing binary wb.
You may also add U to the mode string (e.g. `mode=’rtU’) to
activate universal line end mode, which ensures files are read the same
in Windows, MacOS and Linux.
out = open("output.txt", 'wt')
out.write("Hello file")
out.close()
As seen above, one should always close the file when no more data needs to be written. This also ensures that any information buffered in memory is saved to disk as soon as possible.
Although good practice dictates that one should always .close() our file handles,
when a lot of things need to happen before we are done with the file,
it’s quite easy to forget to do that or even to figure out what is the most
appropriate location to do it.
To make our life easier, Python developers added a with keyword that,
allows Python to perform actions before and after the main event.
As you may have guessed, we can use with and open() together:
with open("output.txt", 'wt') as out:
out.write("Hello file")
and here we open the file in write-text mode, keep a reference to the file handle, write to it and Python takes care of closing it for us.
with and generators
The with keyword is somewhat picky. Not all functions are compatible with it.
If you try to use it with a regular function you will likely see the following exception.
def myfunction():
return ["Yes", "No"]
with myfunction() as out:
print(out)
AttributeError: __enter__
To define our own functions that can work with the with keyword
we need to create a context manager.
Luckily, the contextlib library included in Python contains a contextmanager function
that does exactly this.
contextmanager is a function that takes as input a generator and turns it into
a context manager.
from contextlib import contextmanager
def with_before_and_after(*args, **kwargs):
print(">>> before >>>")
yield "A MESSAGE!!!"
print("<<< after <<<")
managed = contextmanager(with_before_and_after)
Decorating functions
If you are finding the line
contextmanager(with_before_and_after)puzzling you may have seen its other face called decorator.In fact, the above code is equivalent to:
@contextmanager def with_before_and_after(*args, **kwargs): (...)
This function can then be used as:
with managed() as msg:
print("OMG! I have received", msg)
which produces:
>>> before >>>
OMG! I have received A MESSAGE!!!
<<< after <<<
1.11. With great power… comes extra caution
When working with files, you may have been introduced to the
open()function and thewithkeyword. Together they ensure that, once thewithblock finishes, any remaining content is written to disk and the file is automaticallyclose()‘d.Your code may look like:
with open("outputfile.csv", 'w') as out: value = x / y out.write(f"{value}\n")However, consider the situation where
yis0and aZeroDivisionErrorexception happens. If unhandled, thewithwill ensure the file isclosed()but you will be left with a half-written (or corrupted) file.To avoid this situation your task is to create a better version of
open()that we will callsafe_write().safe_write()should do the same asopen()inwtmode, but in addition should delete the file if an error occurs.To make your life easier, consider using the versatile
contextmanagerfromcontextliblibrary.With your solution, the following code should raise a
ZeroDivisionErrorandI_should_be_deleted.csvshould not remain once the script finishes. (The standard library moduleosincludes aremovefunction that can help you with this part.)with safe_write("I_should_be_deleted.csv") as out: value = 500 / 0 out.write(f"{value}\n")similarly, this should create the file
I_should_exist.csvcontaining the value50:with safe_write("I_should_exist.csv") as out: value = 500 / 10 out.write(f"{value}\n")Solution
Useful standard library modules
Globbing patterns
When working with files, it is also often useful to pattern match files based on their
filename, extension or a combination of both.
If you are used to working in a shell or command-line you have probably seen instructions
like ls *.csv which lists all .csv files in the current folder.
We can do the equivalent in Python by using the functions in the glob module,
more specifically, glob.glob or its iterator cousin glob.iglob:
from glob import iglob
for filename in iglob("*.csv"):
new_filename = f"new_{filename}"
with open(new_filename, 'wt') as fh:
print("Doing something with", new_filename)
fh.write(f"Hello! I was created from {filename}")
which creates a file new_<filename>.csv for every <filename>.csv file in the current directory.
Convenient collections
Another module in the standard library, collections,
contains a number of specialised objects designed to handle common tasks when
working with collections of values.
It provides ordered dictionaries,
which remember the order in which items were added
(less useful since Python version 3.6),
named_tuples,
which allow lookup of named attribute values (e.g. beehive.queen)
without the hassle of defining a whole new class,
and deques,
which are extremely powerful when working with containers of a pre-defined size
whose members are expected to frequently change and rotate positions.
Here, we’ll focus on two more classes from collections that we use most often:
Counter and defaultdict.
Counter provides an efficient way to count occurances of values
within a collection.
Once created, a Counter object can be treated similarly to a dictionary:
from collections import Counter
nucleotide_frequencies = Counter('ACGUGUCGAACUAACGCC')
print(nucleotide_frequencies['C'])
long_string = """
This is the tale of a tiny snail, and a great big, grey blue, humpback whale. This is a rock, as black as soot, and this is a snail with an itchy foot.
The sea snail slithered all over the rock, and gazed at the sea and the ships in the dock.
"""
word_counts = Counter(long_string.replace(',', '').replace('.', '').lower().split())
print(word_counts['this'])
6
3
defaultdict can save you some time if you know in advance the kind of data
you expect to collect as values in a dictionary.
When iteratively populating a native dict dictionary -
sometimes adding to/adjusting entries already present in the dictionary,
sometimes creating new entries -
it is necessary to separately specify what should happen when
a key is being used for the first time.
defaultdict allows us to define a function that will be used to intialise the
defualt value when a new key is used
to access the defaultdict object for the first time:
from collections import defaultdict
input_data = """human eyes
canary wings
human teeth
canary beak
canary eyes
platypus beak"""
features = defaultdict(set)
for line in input_data.split('\n'):
organism, feature = line.split()
features[organism].add(feature)
print(features["human"])
{'eyes', 'teeth'}
More useful standard modules
os.*andsys- functions to work with the file and operating systemitertools.*- a collection of functions that implement efficient algorithms on top of iterators/generators for good resource managementfunctools.*- a collection of functions that take as inputs other functions.
1.12. Maintaining order
Correct the following code such that it produces the expected output:
from collections import Counter data = {1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 6, 1, 3, 4, 6, 3, 4, 4, 4, 4} counts = Counter(data) for value in counts: print(value, "* " * counts[value]) print(" 1 2 3 4 5 6 7 8 9")should generate:
6 * * * 5 * 4 * * * * * * * 3 * * * * 2 * * 1 * * * 1 2 3 4 5 6 7 8 9Solution
1.13. Collections counter
Use a dictionary, and
collections.defaultdictandcollections.Counterto count the number of unique strings in the following list of stringsGiven:
list_of_strings = ['apple', 'banana', 'melon', 'banana', 'banana', 'apple', 'grape' , 'grape', 'cthulhu']the output should be of the form
{'banana': 3, 'apple': 2, 'grape': 2, 'melon': 1, 'cthulhu': 1}Solution
Python code in the wild
Python is both a rich and dynamic language containing hundreds of useful functions in its standard library. This lesson is pretty long, and we barely scratched the surface!
On top of this, new features keep being added as newer versions of Python are released, further expanding the number of possibilities and improving expressivity and performance.
Furthermore, and as you’ll see in the next chapter, once you go beyond the standard library the Python ecosystem is brimming with useful libraries for all kinds of purposes.
Additional syntax & latest features
There are some more elements of Python syntax that we haven’t covered here, which we briefly describe below. Follow the links for recommended resources to learn more about each one.
_,__- single, double underscore - usually as prefix to variable names, used to represent private or internal variablesif __name__ == "__main__":- present at the bottom of modules - specifies code that should run when the script executed but not when it’simported.classes - an extremely powerful construct - you have probably already used them without realizing it.The features below were added in the most recent major release of Python (at time of writing), version 3.8:
yield from- syntax to delegate to sub-generatorstypingmodule - type annotations / hints - see also mypy:=- walrus operatorasync/await/asyncio- a collection of components to handle asynchronous I/O*and/- in function argument definitions - allowing exclusively positional and keyword arguments.
Additional resources
- An intermediate python book with sections on
collections,exceptions, context managers and much more
Key Points
Use comprehensions to create new iterables with a few lines of code.
Sets can be extremely useful when comparing collections of objects, and create significantly speed up your code.
The
itertoolsmodule includes many helpful functions to work with iterables.A decorator is a function (or class) that adds behavior to other functions (or classes) without modifying their inner code